Python爬虫
网络爬虫简介
网络爬虫又称网络蜘蛛、网络蚂蚁、网络机器人等,可以自动化浏览网络中的信息,也可以自动化收集数据。当然这需要按照我们制定的规则进行,这些规则我们称之为网络爬虫算法。
例如搜索引擎离不开爬虫,百度搜索引擎的爬虫叫作百度蜘蛛(Baiduspider)。百度蜘蛛每天会在海量的互联网信息中进行爬取,爬取优质信息并收录,当用户在百度搜索引擎上检索对应关键词时,百度将对关键词进行分析处理,从收录的网页中找出相关网页,按照一定的排名规则进行排序并将结果展现给用户。
为什么选择Python
使网络爬虫的编写变得简单
网络爬虫一个广泛的定义就是它可以模拟人的行为去浏览网页,那么python提供了功能强大的库来帮助我们模拟人的行为去访问服务器、浏览网页,如requests模块。另外python也对文本处理,数据分析等功能有着大量功能强大的库进行支持。最重要的就是python语法简单,适合新手入门^_^
网络爬虫开发的前期准备
用python来开发当然要安装python开发环境,编写程序可以用python自带的IDLE或者其它IDE如Anaconda、Pycharm等等都可以,本篇博客使用的是VS Code。安装好了python开发环境后首先就要下载安装requests模块:
- 使用pip进行安装:
1 | $ pip install requests |
如果下载速度慢,下载站点可以使用国内的清华镜像站:
1 | $ pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests |
下面我们就来用面向过程的方法进行一个python原生爬虫的小项目实战开发——爬取网络小说的章节目录。
Python原生爬虫的开发
导入所需模块
1 | import requests |
模拟请求,获取网页源代码
1 | url='http://www.xbiquge.la/13/13959/' #小说目录网页的网址 |
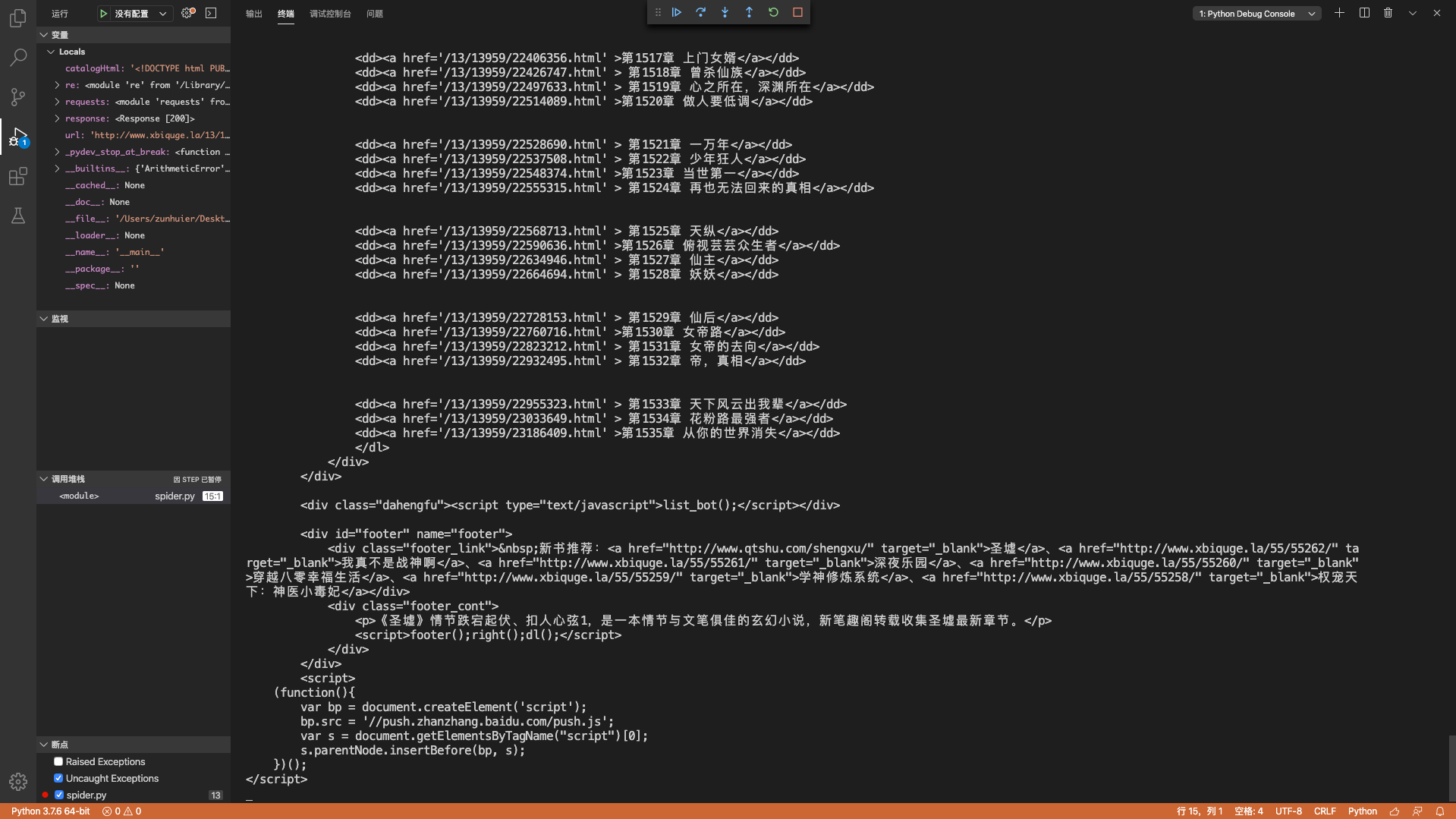
我们可以看一下获取到的HTML源代码:
1 | print(catalogHtml) |
定位数据,采集数据
这一步我们需要用到正则表达式在HTML源代码中对我们所需的数据进行定位,以此来采集我们所需的数据。定位的标准是尽可能的唯一,准确。比如说,<a href="xx">xx</a>这个标签对中就可以匹配出每章章节的URL地址和章节名字。
1 | chapterDiv=re.findall(r'<div id="list">.*?</div>',catalogHtml,re.S)[0] |
我们可以看一下匹配结果:
1 | print(chapter_list) |
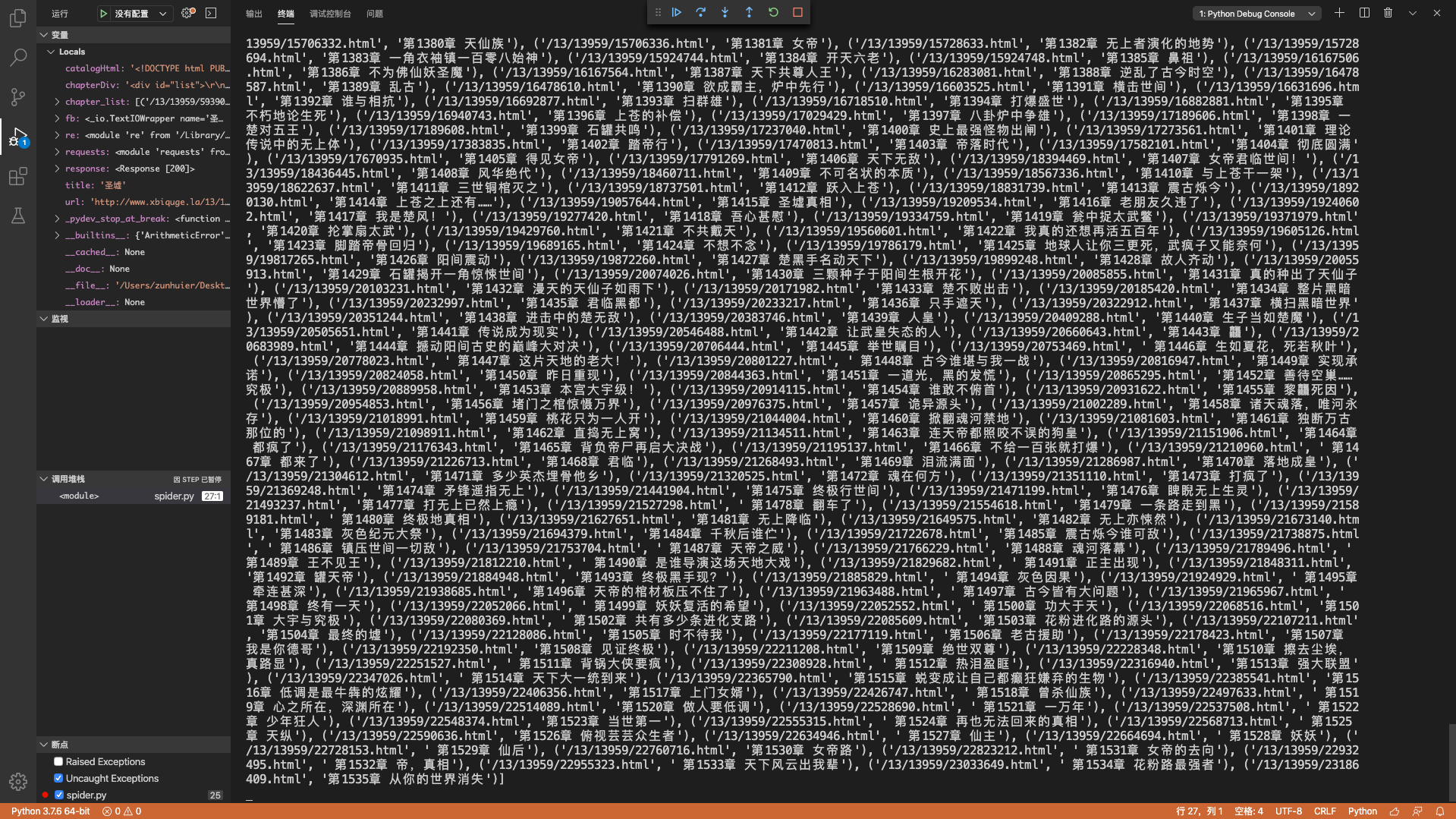
- 可以看出findall函数返回一个匹配结果形成的列表,我会另写一篇博客来专门介绍用来在字符串中匹配特定内容的正则表达式。
清洗数据,打印输出
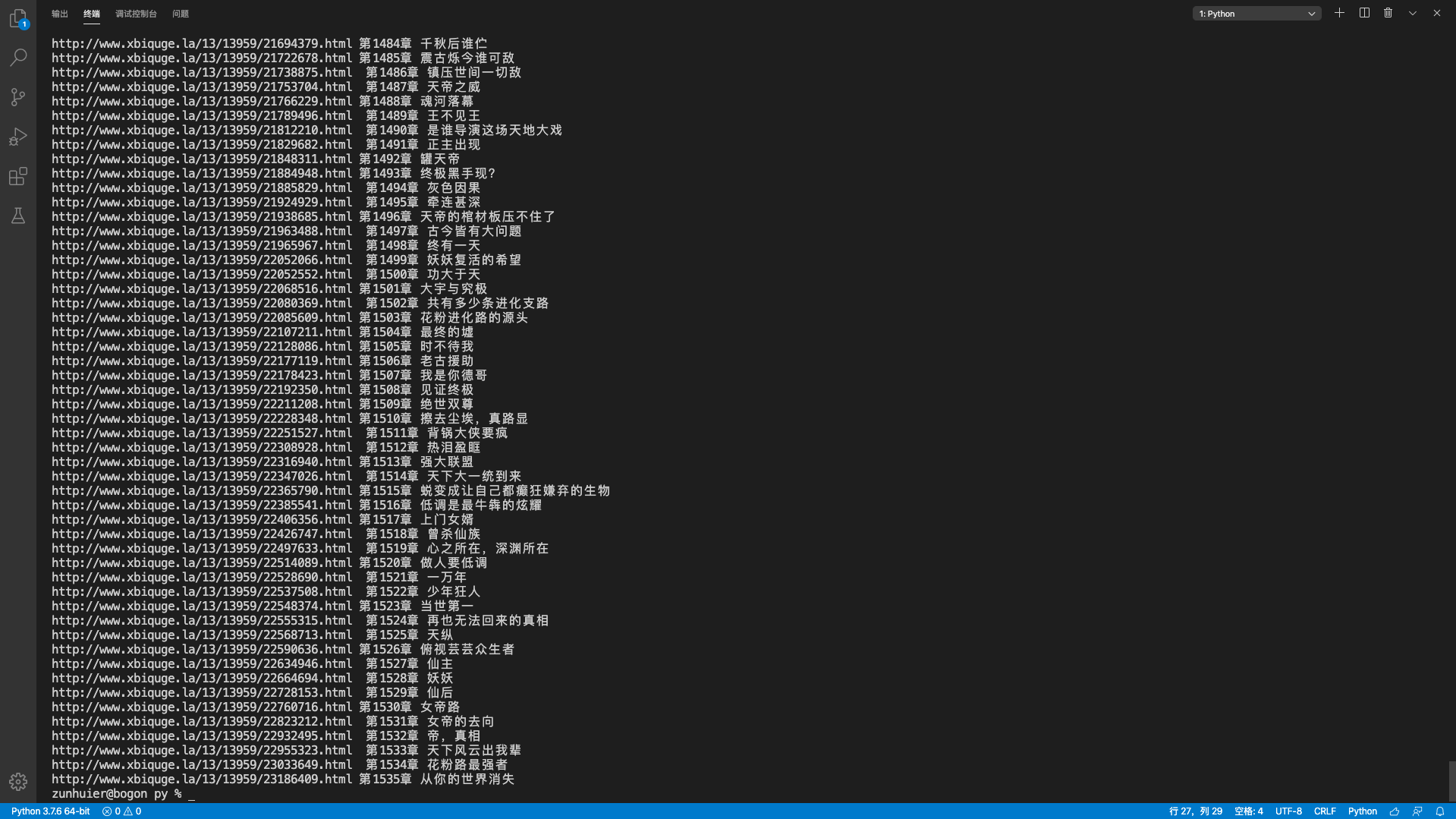
清洗数据就是对采集到的数据进行整理、规范化,使数据更加直观易读。这里我就简单整理了下数据,直接打印输出:
1 | for chapter in chapter_list: |
分析数据
我们已经拿到想要的数据了,接下来就可以利用,分析这些数据,我们还可以拿着上面的章节完整域名继续去爬取每章小说的具体内容^_^具体怎么利用这些数据就看个人了。
但请注意!!!爬虫需谨慎!!!《中华人民共和国网络安全法》!!!
附上完整源代码
1 | import requests |
总结
这是一种最简单的爬虫,只展示了爬虫的基本实现原理,除了python没用到其它更复杂的技术,只能用来完成一些简单的特定功能。当然,爬虫还有更高级的应用,网络上也有着大量优秀的爬虫开源框架。
 微信
微信 支付宝
支付宝