正则表达式
前言
字符串是我们编程时涉及到的最多的一种数据结构,对字符串进行操作的需求几乎无处不在,比如我们使用爬虫时需要在一大片的字符串中定位到我们所需要的数据以便提取数据;打开一个字符流,查找其中特定的内容;对用户输入进来的内容进行检验,防止SQL注入。
正则表达式就是一种用来匹配字符串的强大武器,它的设计思想就是用一种描述性的语言给字符串定义了一个规则,凡是满足这个规则的字符串,我们就说它与这个正则表达式匹配了,否则就是不匹配的。
许多编程语言都支持正则表达式,不同编程语言对正则表达式的支持也有些许不同,这里我用Java语言来实现正则表达式的功能。
需要说明的是,正则表达式的功能非常强大,特性也非常丰富,一篇博客是讲不完的,只能入门正则表达式。如果需要经常与正则表达式打交道,最好还是常备一本正则表达式的参考书。是的,关于正则表达式可以写一本书出来。
Java中支持正则表达式的类库
在java中,String类本身就提供了一个matches方法用来进行正则表达式的匹配,如下面的例子:
1 | public class Demo{ |
结果:
true
- matches方法进行的是全文本匹配,后文会讲到。
Java还提供了一个支持正则表达式的类库:java.util.regex,其中主要包括三个类:
Pattern类:pattern类的对象是一个正则表达式的编译表示。Pattern类没有公共构造方法。要创建一个Pattern对象,你必须首先调用其公共静态编译方法,它返回一个Pattern对象。该方法接受一个正则表达式作为它的第一个参数。
Matcher类:matcher类的对象是对输入字符串进行解释和匹配操作的引擎。与Pattern类一样,matcher类也没有公共构造方法。你需要调用Pattern对象的matcher方法来获得一个Matcher对象。
PatternSyntaxException类:是一个非强制异常类,它表示一个正则表达式模式中的语法错误。
下面看一个例子:
1 | import java.util.regex.*; //导入类库 |
- Matcher类的对象的matches方法也是进行全文本匹配,返回一个布尔值。除此之外,匹配器对象还有需要重复调用以匹配内容符合规则的全部子串的find方法,以及提取分组匹配中内容符合规则的子串的group方法,这些在下面都会讲到。
结果:
true
- 再重申一遍,由于正则表达式也是一个字符串,所以正则表达式中的特殊字符,如’\‘需要在java字符串中转义表示。\w、\d、*,等等是正则表达式的元字符,后文会讲到它们的作用。
下面开始讲解正则表达式
正则表达式是一个字符串
从形式上看,正则表达式也是一个字符串,是一个描述规则的字符串,它规定了另一个符合这个规则的字符串中应该有什么内容,有什么样的内容,或者说另一个字符串中的某个子串的内容符合这个规则。使用正则表达式,就可以去匹配出一个字符串中的特定内容。
全文本匹配
我们除了需要去匹配一个字符串中是否有特定内容,有时还希望去匹配整个字符串或者说文本(文本就是一行一行的字符串,有换行,但本质上就是一个字符串),看它是否符合我们正则表达式的规则,这时就需要对字符串进行全文本匹配。
正则表达式中有两个特殊的定界符:^和$。
^表示字符串开始的位置,$表示字符串结束的位置,如”^a”表示字符串必须以字符’a’开头,”9$”表示字符串必须以字符’9’结束。
举个例子,我们假设区号+电话号是这样一种形式:123-12345678,即满足这样一个规则:必须以3个数字开头,中间以一个英文的破折号’-‘分隔,再以8个数字结尾。我们可以写出正则表达式如下:
^\d{3}-\d{8}$
- 关于这个正则表达式的元字符和限定符下面会讲。
凡是用这个正则表达式去匹配成功的字符串,我们就可以认为它是合规的电话号码。如”110-11079117”是合规的,”a110-12345678”、”110-12345678a”、”110+12345678”、”110-123456789”等等都是不合规的。
注意,java中的matches方法就是进行全文本匹配,不用再加这两个定界符了(单独的写全文本匹配的正则表达式才需要加),所以用matches方法进行匹配的字符串必须整体满足正则表达式的规则才能匹配成功。
精确匹配
比如我们有一个字符串:"I'am java, I love java.",想要知道里面有没有java这个内容或者说子串,我们可以这样写java代码:
1 | String context="I'am java, I love java."; //待匹配的字符串 |
- 关于find方法:find方法通过循环调用,可以去遍历整个字符串,找出符合规则的全部内容或者说子串,每一次可以通过group()方法返回当前找到的符合规则的子串。find方法也可以进行全文本匹配,只需在正则表达式中加上两个定界符就可以了。group方法在后面分组匹配的时候再讲。
这样可以匹配出两个结果:
起始位置:5------java------结束位置:9
起始位置:18------java------结束位置:22
像"java"这样直接给出明确字符的正则表达式去匹配明确内容的情况,我们叫做精确匹配。
模糊匹配
精确匹配在实际应用中用处不大,因为String类本身就提供了equals方法实现了精确匹配的功能。而且大多数情况下,我们想要进行的是模糊匹配,也就是可以匹配任意字符,也可以匹配限定任意个数的任意字符。
在模糊匹配下,我们只是给字符串设立了一个规则,在满足这个规则的前提下,我们匹配出的字符有多少个我们并不知道,比如上面那个电话号码的例子,我们可以重新设立必须以3~8个数字结尾的规则,那这样我们匹配成功的字符串,可能是以5个数字结尾的,也可能是以6个数字结尾的。
这时候我们就需要使用正则表达式的元字符的功能。
元字符
我们需要一些特殊字符去匹配一个任意字符,下面列出一些常用的元字符和它们的功能:
| 元字符 | 功能 |
|---|---|
| \ | 将后一个字符转义,例如,’n’匹配字符’n’,而’\n’匹配一个换行符。’\\‘匹配’\‘,’\(‘则匹配 ‘(‘ |
| . | 匹配除换行回车符(\n,\r)之外的一个任意字符 |
| \n | 匹配一个换行符 |
| \r | 匹配一个回车符 |
| \t | 匹配一个制表符 |
| \d | 匹配一个任意的数字字符 |
| \D | 匹配一个任意的非数字字符 |
| \w | 即word,匹配一个任意的字母或数字或下划线字符 |
| \W | 匹配一个任意的非字母、数字、下划线的字符 |
| \s | 匹配一个任意的空白字符,包括空格,换行回车符,制表符等等 |
| \S | 匹配一个任意的非空白字符 |
| \un | 匹配一个Unicode字符,其中n由四位十六进制数组成 |
容易发现,元字符的大小写功能完全相反。 我们可以用java代码测试一下这些元字符:
待匹配的字符串:
1 | String context = "我I'am java, I love java, I'm 25."; |
不同的正则表达式(注意转义问题):
1 | ... |
1 | ... |
1 | ... |
1 | ... |
1 | ... |
1 | ... |
匹配指定范围的字符
正则表达式中有一类特殊的元字符,它可以用来匹配指定范围的字符,形式为:[xyz]。
[xyz]表示一个字符集合,匹配其所包含的任意一个字符。它还有一种不包含的写法,如[^x],匹配除字符x之外的任意一个字符
例如,[abcdef]可以匹配出”apple”中的’a’和’e’,[123456789]可以匹配出任意一个其中包含的数字字符,即1~9。
但是这样把要匹配的字符一个一个写进去太麻烦了,有一些常用的简便写法如下:
| 匹配范围 | 功能 |
|---|---|
| [0-9] | 匹配一个0~9的数字字符,等价于元字符’\d’ |
| [^0-9] | 匹配一个非0~9的任意字符,等价于’\D’ |
| [a-z] | 匹配一个任意的小写字母字符 |
| [A-Z] | 匹配一个任意的大写字母字符 |
| [^a-z] | 匹配一个任意的非小写字母的字符 |
| [a-zA-Z0-9_] | 匹配一个小写或大写字母字符或数字字符或下划线,等价于’\w’ |
我们还是用上面的待匹配字符串测试一下:
1 | ... |
1 | ... |
限定符
前面写的正则表达式中,不管是明确的字符’a’,还是元字符’\w’,它们在表达式中出现一次就代表匹配一次,在匹配成功出来的内容或者说子串中出现一次这个字符。例如,表达式”a\wc”,代表要匹配出的内容中有3个字符,可能是”abc”或者”a6c”或者”a_c”,这些字符串都符合规则。
还有一类特殊的元字符,可以用来指定正则表达式中前一个字符或者子表达式的匹配次数,有下面三种:
| 限定符 | 功能 |
|---|---|
| * | 匹配前面的一个字符或子表达式零次或多次。例如,”zo*”能匹配出”z”、”zo”以及”zoooooo” |
| ? | 匹配前面的一个字符或子表达式零次或一次。例如,”do(es)?”可以匹配出”do”或”does” |
| + | 匹配前面的一个字符或子表达式一次或多次。例如,”zo+”能匹配出”zo”以及”zoo”,但不能匹配出”z”,即至少匹配一次 |
我们还是用上面的待匹配字符串测试一下:
1 | ... |
- 可以看出跟上面单独一个正则表达式
\w的例子匹配出来的结果不同,这里相当于把字符串切分了(忽略中文)。没错,你可能已经联想到了,正则表达式还可以用来切分字符串,而且比一般编程语言里面自带的切分字符串的方法更加强大,灵活。这里只是简单提一下,这篇博客并不会深入去讲。
限定符还有另外一种写法,形式如下面几种:
| 限定符 | 功能 |
|---|---|
| {n} | n是一个非负整数,匹配前面的一个字符或子表达式n次 |
| {n,} | 匹配前面的一个字符或子表达式n次或多次,即至少匹配n次 |
| {n,m} | m和n均为非负整数,其中n<=m。匹配前面的一个字符或子表达式最少n次,最多m次 |
| {1,} | 等价于限定符 + |
| {0,1} | 等价于 ? |
| {0,} | 等价于 * |
我们还是用上面的待匹配字符串测试一下:
1 | ... |
- 这里匹配出许多空字符,是因为
{0,}就相当于*,两者都可以指定匹配前面的一个字符或子表达式零次或多次。所以在字符串中,遇到非数字字符,就相当于正则表达式用\d匹配了零次,这种规则下当然就匹配出了空字符,也当成结果返回。
贪婪匹配和非贪婪匹配
贪婪匹配
在上面的一个例子中,正则表达式\w+相当于把字符串切分了,从这里可以看出,在正则表达式中,在一个字符或子表达式后面加上限定符后,默认进行的是贪婪匹配,也就是说,在这个例子的匹配的过程中,正则表达式遇到一个\w代表的字符后,其实它已经满足了限定符+指定的至少一次的匹配次数,但它还不满足,想要继续匹配下去,直到遇到非字母,非数字,非下划线的字符才停止这次匹配。之后它会跳过这些不符合规则的字符,去后面继续匹配出符合规则的字符。所以这就是为什么,这个例子中的字符串看上去是以空格、逗号进行切分的。
我们还是以我I'am java, I love java, I'm 25.这个字符串进行举例:
1 | ... |
- 可以看出,即使中间已经出现了java这个字符串,前面也是符合
.*的字符串,也就是说我I'am java这个子串已经符合正则表达式的规则了。但它还是会继续匹配下去,直到匹配出最后一个java字符串为止,因为我I'am java, I love java这个子串也符合规则,那它就要“贪婪“一点。
贪婪匹配就是尽可能多的匹配出符合规则的内容。
非贪婪匹配
非贪婪匹配也称惰性匹配,只要在一个限定符后面加上一个?就可以进行惰性匹配了。
我们还是以我I'am java, I love java, I'm 25.这个字符串进行举例:
1 | ... |
- 可以看出,非贪婪匹配只要匹配出了符合规则的内容就进行返回,即去匹配尽可能少的内容。
分组匹配
()在正则表达式中有一个重要的作用,就是进行分组匹配。分组匹配的功能就是在一个匹配出的符合正则表达式规则的字符串中,提取特定子串出来。
- 在java中,通过
Matcher.group(index)方法提取子串:- group()与group(0)等价,返回的是整个正则表达式匹配出的内容
- group(i)返回的是正则表达式中从左往右数第i个分组里的内容
- 分组就是正则表达式中用
()括起来的子表达式
我们来看下面两个例子:
1 | public class Demo{ |
1 | public class Demo{ |
总结
正则表达式非常强大,在一篇博客中是讲不完的,这篇博客只是简单的入门正则表达式。我们只需记住正则表达式可以用来匹配字符串中的特定内容就行了。
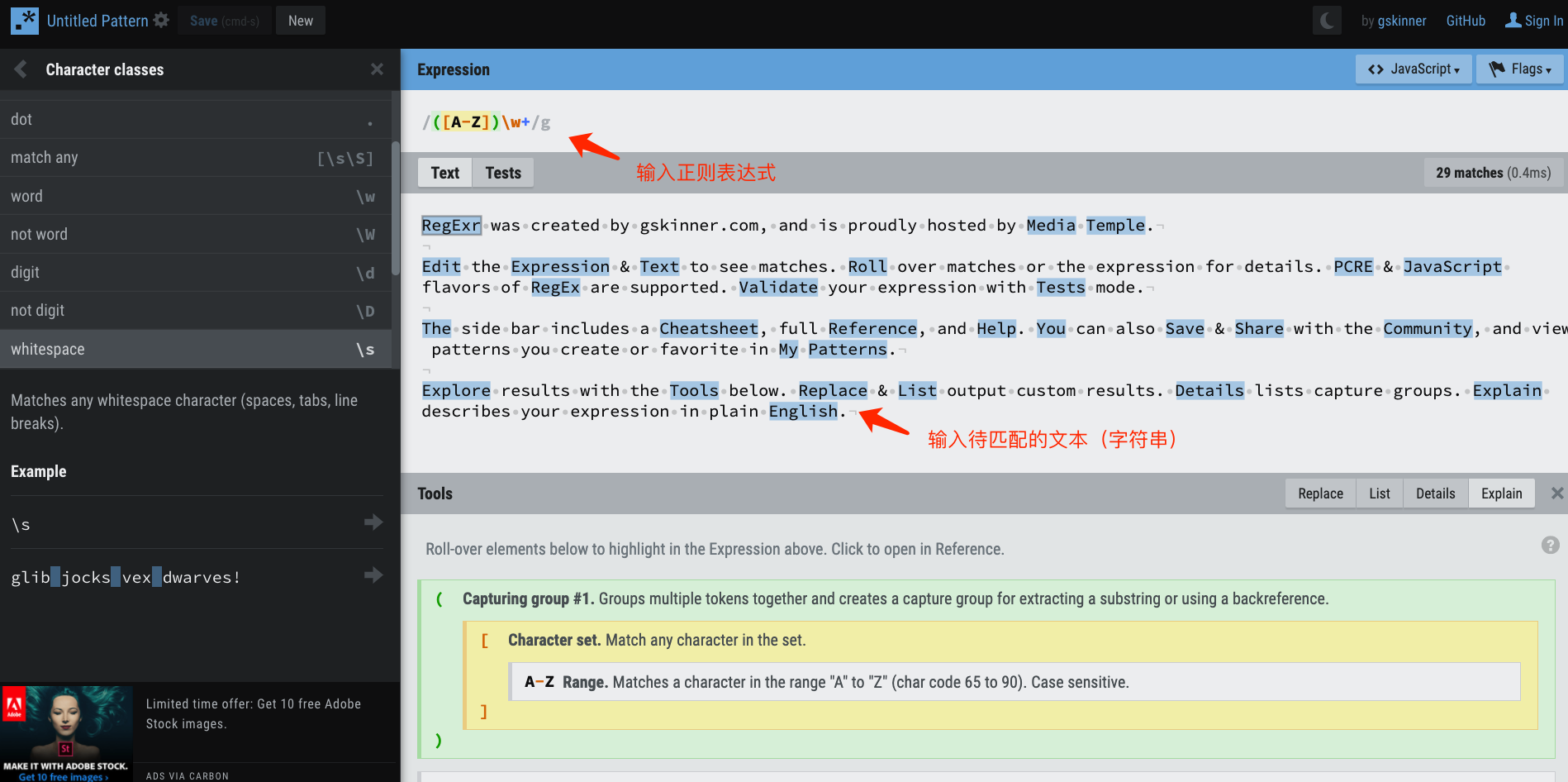
在线正则表达式测试网站
这里推荐一个正则表达式的在线测试网站:
 微信
微信 支付宝
支付宝